تعرف على تقنية Deep fake الخطيرة لتغيير وجه شخص في الفيديو بجودة عالية

لم يمضي وقت كبير عندما قام أحد مستخدمي منصة reddit يسمى ديب فيك Deep fake بنشر فيديوهات واقعية وذات جودة جد عالية لكنها مزورة نعم صديقي مزورة.
هذه الفيديوهات قد قد تم التلاعب بها باستخدام خواريزمية دراسة عميقة ( (Deep learning algorithm قام من خلالها بتغيير وجوه فنانين مشهورين بوجوه أخرى لأشخاص مشهورة. لكن قبل أن تسألني صديقي. سأجيبك. نعم، لقد كانت فيديوهات ذات محتوى للبالغين فقط.
أكيد أن السؤال الذي يتبادر لذهنك الآن هو كيف يتم ذلك ؟ هذا ما سأشرحه لك ؟
لشرح هذه الخواريزمية سنقسمها لثلاث فقرات هي في الحقيقة المراحل الثلات التي يمر منها تزوير الفيديو:
لكن قبل الخوض في المرحلة الأولى يتم جمع صور كثيرة للشخصية المراد تركيبها في الفيديو الأصلي أي التي سيتم تغيير وجه الشخصية الأصلية ووضع وجهه.
⦁ المحاذاة align
الهدف كما قلنا من تقنية deepfake هو تغير الوجوه وبالتالي فأول مرحلة نقوم بها هي التعرف على موقعها في الصور حتى يتسنى لنا معرفة اتجاهاتها وحجمها، فباستخدام هذه المعلومات سنتمكن من تشويه كل الصور بشكل عام.
وللقيام بذلك يمكن استخدام تقنية معروفة ومعقدة تسمى histogram of oriented Gardiants والتي يرمز لها ب HOG هذه التقنية تقوم بأخد كل بيكسل في الصورة وتقوم بمقارنة مدى ظلمتها بالبيكسل المحيطة بها، لتقوم برسم منحنى من الأقل إلى الأكثر غمق أو ظلمة.وهناك العديد من أنماط HOG التي سبق تدريبها على ألاف الصور. فبعد استخلاص المعلومات من صورنا الأصلية يتم مقارنتها بهذه الأنماط لتحديد المناطق المشابهة وبالتالي تحديد منطقة الوجه.
هذه الصورة ستوضح الأمر بشكل أكثر
الوجه المتواجد على اليمين الذي به مربع أصفر هي صورتنا الأصلية والتي على اليسار هي النمط المستخلص من العديد من الصور والوجوه..فالمربع الأصفر هو المنطقة المشابهة للنمط المتوفر في Hog وبالتالي تم التعرف عليه كأنه وجه.

⦁ التدريب train
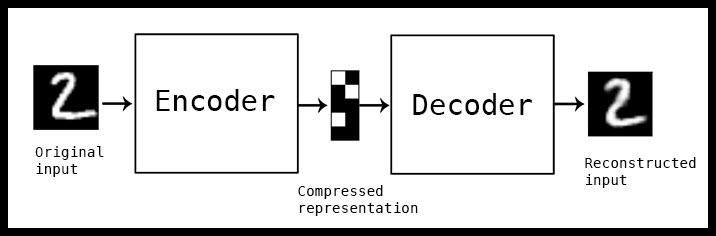
باستخدام مستخرجات صور الوجوه نستطيع تدريب مشفر تلقائي autoencoder .
ال autoencoder هو نوع من الشبكات العصبونية ( تقنية متطورة تستخدم في الذكاء الصناعي وما يسمى يالتعلم العميق deep learning), مدخلاته تكون عبارة عن صورة ومستخرجاته الصورة نفسها.
قد تظن أن هذه الجملة ليس لها معنى لكن انتظر سأشرح لك.
المشفر التلقائي أو autoencoder يتكون من جزأين :
التشفير encoder : هذا الجزء من الشبكة يقوم بتحويل المدخلات أي الصورة إلى عدد من bits (0 و 1) وتسمى المساحة التي يمثلها عدد أقل من bits ب “latent-space ” أما نقطة الضغط الأقصى فتسمى “bottleneck” فهذه bits المضغوطة تسمى مشفر « encoder ».
فك التشفير Decoder: هذا الجزء من الشبكة هو من يقوم بإعادة بناء صورة الإدخال من خلال ترميز الصورة.
في هذا الجزء نقوم بتدريب نموذجنا على الصور المستهدفة حيث تقوم شبكتنا بتعلم كيفية ترميز تمثيل قصير في وجوه الأشخاص المستهدفة لدينا، بمعنى حتى لو كانت مدخلاتنا عبارة عن وجه مختلف فسيقوم نموذجنا بتحويلها إلى وجه الشخصية الأصلية.
الآن يمكننا تعريف الوجوه في الفيديو الخاص بنا (الفيديو كما هو معروف عبارة عن العديد من الصور المتسلسلة) وإدخالهم لنموذجنا الذي سبق تدريبه ليقوم بتحويل الشخصية الأصلية للشخصية المستهدفة.⦁ الدمج Merge:
في هذا الجزء سنأخذ الصور المستخرجة من autoencoder.و باستخدام المعلومات المستخلصة في المرحلة الأولى من توجيهات الصور وحجمها،ومع بعض الهندسة الخلفية سنقوم بوضعهم في الصور الأصلية. وهكذا سنقوم بإعادة صنع الفيديو باستخدام الصور المعدلة. هذا كل شيء الآن لدينا فيديو deepfake جديد جاهز.

الأكيد أن هناك الكثير من التفاصيل الأخرى المعقدة لكن تبقى هذه هي المبادئ الأساسية لاشتغال الخواريزمية، كما أن المقال الهدف منه توضيح العملية ومدى تعقيدها خصوصا مع الضجة التي أحدثها هذا الموضوع مؤخرا.
كما يجب الإشارة إلى أن المقالة تحتوي العديد من المصطلحات المعقدة وقد حاولنا تبسيطها بقدر المستطاع،لكن يمكنك البحث في اليوتوب ومحرك البحت جوجل لتجد العديد من الشروحات المبسطة،رغم أن أغلبها باللغة الإنجليزية لأنه للأسف المحتوى العربي ضعيف نوعا ما في هذا المجال.